"Elf-Disclosure" for Mar 2024
We're 8-months old now, and have just completed our (first!) April 2024 price "normalization" since the app prices were "guessed" at, way back in the beginning.
We suffered through some "growing pains" in the first half of March, and then spent the second half bedding in and seeking stability while working on the the price refresh. The focus on stability drove improvements to our deployment / testing process, and moved our bug / feature tracking from Discord to GitHub.
To get us started, here are some shiny stats for Mar 2024, followed by a summary of some of the user-facing changes announced this month in the blog...
Stats
| Money | Jan 2024 | Feb 2024 | Mar 2024 |
| Cluster | $1400 | $2540 | $2540 |
| Store | $56 | $56 | $56 |
| CI | $100 | $100 | $100 |
| Cloud | $20 | $20 | $20 |
| Development | 90h / $13,500 | 120h / $18,000 | 90h / $13,500 |
 OSS Sponsorship OSS Sponsorship | - | $154 | $35 |
| Total Expenses | $15,230 | $20,870 | $16,251 |
| Income | $665 | $1225 | $1525 |
| Income % of cash expenses | 38.4% | 42.6% | 53.14% |
| Income % of all expenses | 4.36% | 5.87% | 9.38% |
| Focus | Jan 2024 | Feb 2024 | Mar 2024 |
| Subscribers | 183 | 325 | 413 |
| Ingress | 65TB | 52TB | 150TB |
| Egress | 23TB | 21TB | 58TB |
| Pods | 2211 | 4097 | 3446 |
| Focus | Jan 2024 | Feb 2024 | Mar 2024 |
| Unique visitors | 6.9K | 13K | 15.7K |
| Total pageviews | 25.9K | 50K | 54.9K |
| Discord members | 320 | 525 | 702 |
| Focus | Jan 2024 | Feb 2024 | Mar 2024 |
| Total invested thus far | $87,049 | $107,919 | $124,170 |
| Total revenue | $2,070 | $3,295 | $4,820 |
| Income % of total invested | 2.38% | 3.01% | 3.88% |
Resources
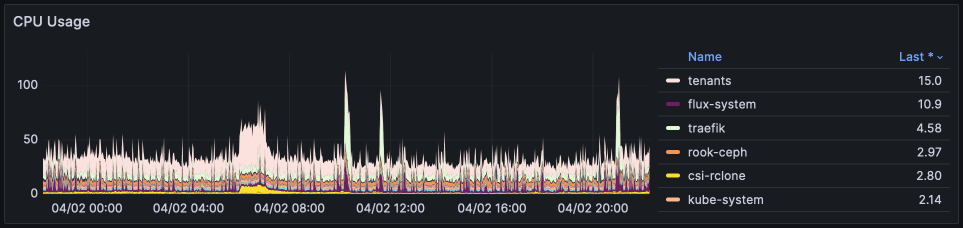
The stats below indicate CPU cores used (not percentage), and illustrate that after tenant workloads, our highest CPU consumers are traefik and flux. Both of these are unexpectedly high, and while we can absorb the extra CPU usage based on current loading, these are an overhead I'd like to see reduced.
Traefik's CPU usage is high because we run Traefik as a daemonset, meaning we have > 22 pods, each of which gets "excited" when there's a lot of pod churn, and clocks in some heavy CPU usage.
Flux's CPU usage is high because we run 26 shards to spread out the load of reconciliations, but as we add more tenants, this load continues to increase.
The "last" values on the chart are specific to when the snapshot was taken, but what's interesting overall is the higher proportion of tenant CPU load to "other" CPU loads over the period, compared to the previous month:
kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
dwarf01 196m 2% 24121Mi 75%
dwarf02 191m 2% 24807Mi 77%
dwarf03 226m 2% 24739Mi 77%
dwarf04 265m 3% 25252Mi 79%
dwarf05 226m 2% 24615Mi 77%
dwarf06 319m 3% 26056Mi 81%
dwarf07 231m 2% 24789Mi 77%
dwarf08 231m 2% 25307Mi 79%
dwarf09 238m 2% 24735Mi 77%
dwarf10 177m 2% 24846Mi 78%
elf01 3223m 20% 32514Mi 25%
elf02 5298m 33% 43428Mi 33%
elf03 3088m 19% 29308Mi 22%
elf04 3434m 21% 33001Mi 25%
elf05 3593m 22% 34478Mi 26%
elf06 2566m 16% 35722Mi 27%
elf07 4664m 29% 33154Mi 25%
elf08 2778m 17% 35095Mi 27%
elf09 5840m 36% 36044Mi 28%
elf10 3239m 20% 31664Mi 24%
elf11 3744m 23% 39495Mi 30%
elf12 3189m 19% 32400Mi 25%
elf13 3816m 23% 41779Mi 32%
elf14 3158m 19% 43339Mi 33%
elf15 3152m 19% 33155Mi 25%
elf16 3581m 22% 39638Mi 30%
elf17 4916m 30% 46629Mi 36%
elf18 4901m 30% 31646Mi 24%
elf19 3558m 22% 30068Mi 23%
elf20 3830m 23% 40948Mi 31%
elf21 8439m 52% 27345Mi 21%
elf22 3829m 23% 44281Mi 34%
elf23 3327m 20% 48971Mi 38%
fairy01 1352m 8% 38511Mi 29%
fairy02 4059m 25% 46941Mi 36%
fairy03 3720m 23% 52735Mi 40%
giant01 553m 4% 16587Mi 25%
giant02 896m 7% 14111Mi 21%
giant03 669m 5% 16756Mi 26%
gnome01 304m 3% 11884Mi 18%
gnome02 327m 4% 11870Mi 18%
gnome03 1247m 15% 46678Mi 72%
gnome04 375m 4% 12844Mi 20%
goblin04 377m 3% 58443Mi 45%
goblin05 479m 3% 91935Mi 71%
goblin06 383m 3% 80246Mi 62%
Last month (Feb 2024)'s for comparison:

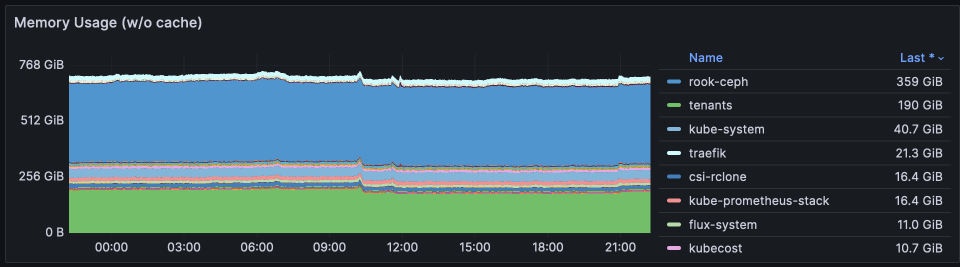
This graph represents memory usage across the entire cluster. By far the largest consumers of RAM is rook-ceph, since ceph will basically take all the RAM you give it, for caching / performance.
RAM usage for tenants has only increased by ~5%, while RAM for the kube-apiserver has increased by 25% (kube-system's increase from 30GB to 40GB). This may be due to the increase in Stremio addons, which generally require low resources, but represent an additional tenant in the system, with the accompanying resources.
kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
dwarf01 196m 2% 24121Mi 75%
dwarf02 191m 2% 24807Mi 77%
dwarf03 226m 2% 24739Mi 77%
dwarf04 265m 3% 25252Mi 79%
dwarf05 226m 2% 24615Mi 77%
dwarf06 319m 3% 26056Mi 81%
dwarf07 231m 2% 24789Mi 77%
dwarf08 231m 2% 25307Mi 79%
dwarf09 238m 2% 24735Mi 77%
dwarf10 177m 2% 24846Mi 78%
elf01 3223m 20% 32514Mi 25%
elf02 5298m 33% 43428Mi 33%
elf03 3088m 19% 29308Mi 22%
elf04 3434m 21% 33001Mi 25%
elf05 3593m 22% 34478Mi 26%
elf06 2566m 16% 35722Mi 27%
elf07 4664m 29% 33154Mi 25%
elf08 2778m 17% 35095Mi 27%
elf09 5840m 36% 36044Mi 28%
elf10 3239m 20% 31664Mi 24%
elf11 3744m 23% 39495Mi 30%
elf12 3189m 19% 32400Mi 25%
elf13 3816m 23% 41779Mi 32%
elf14 3158m 19% 43339Mi 33%
elf15 3152m 19% 33155Mi 25%
elf16 3581m 22% 39638Mi 30%
elf17 4916m 30% 46629Mi 36%
elf18 4901m 30% 31646Mi 24%
elf19 3558m 22% 30068Mi 23%
elf20 3830m 23% 40948Mi 31%
elf21 8439m 52% 27345Mi 21%
elf22 3829m 23% 44281Mi 34%
elf23 3327m 20% 48971Mi 38%
fairy01 1352m 8% 38511Mi 29%
fairy02 4059m 25% 46941Mi 36%
fairy03 3720m 23% 52735Mi 40%
giant01 553m 4% 16587Mi 25%
giant02 896m 7% 14111Mi 21%
giant03 669m 5% 16756Mi 26%
gnome01 304m 3% 11884Mi 18%
gnome02 327m 4% 11870Mi 18%
gnome03 1247m 15% 46678Mi 72%
gnome04 375m 4% 12844Mi 20%
goblin04 377m 3% 58443Mi 45%
goblin05 479m 3% 91935Mi 71%
goblin06 383m 3% 80246Mi 62%
Last month (Feb 2024)'s for comparison:

The network graphs have been reworked for this report, to represent the two points where throughput varies.. the 10Gbps "giant" nodes (which are primarily used for ingress, as incoming Debrid content is passed to elves for streaming), and the 1Gbps "elf" nodes which are our general workhorses.
The graphs below show that the giants are not exceeding 20% of their capacity, but that the 2 elves have (in the past 24h, in this graph) hit their 1Gbps ceiling. This may indicate that we need to better "spread out" high-throughput apps such as Plex across all the elves.
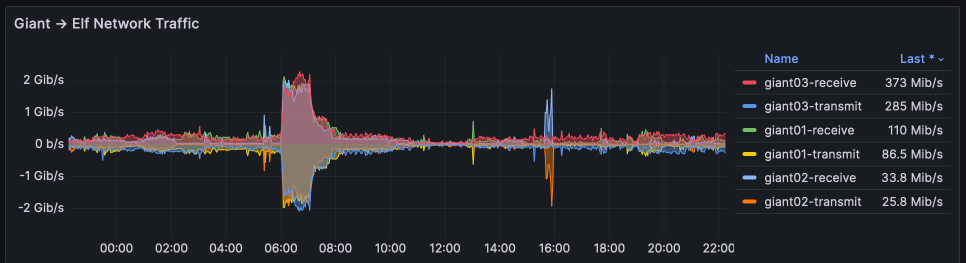
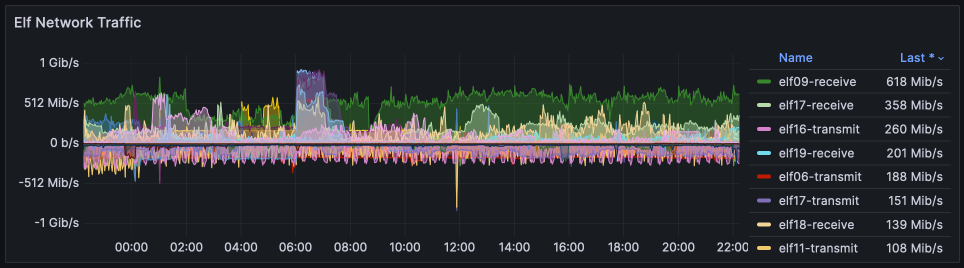
These are the traffic stats for egress from Hetzner. They exclude any traffic to/from Hetzner Storageboxes, and they also exclude stats from any nodes which were decomissioned during the period, which for March was again a lot (we scaled as far as elf27 before scaling back when the Ceph i/o issue was resolved). Thus, these stats are likely under-reported for March.
We also wouldn't see the resulting network traffic to ElfStorage or Storageboxes though, since this traffic is not counted as being "external".
Ingress / Egress stats for Mar 2024
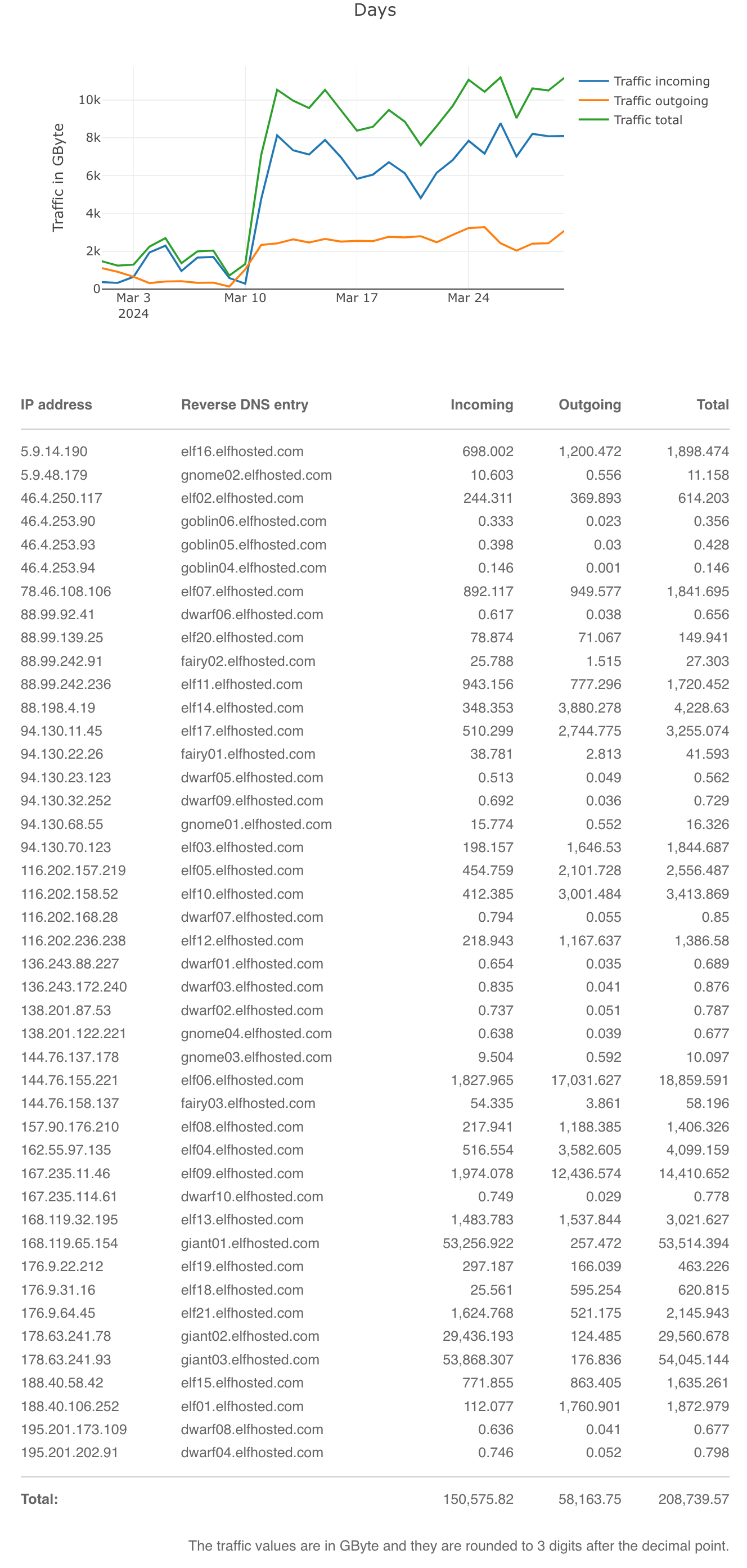
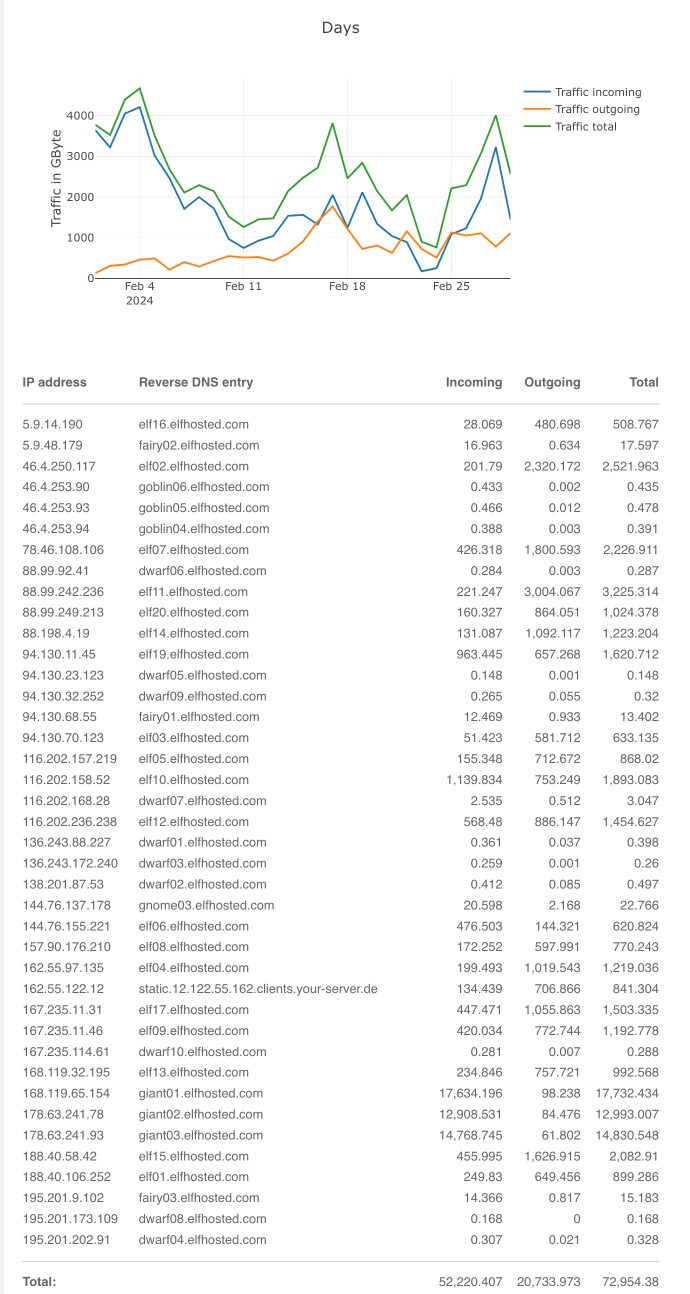
Last month (Feb 2024)'s for comparison:
Ingress / Egress stats for Feb 2024
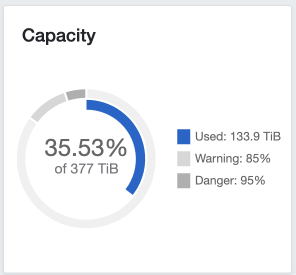
Ceph provides our own storage ("[ElfStorage][elfstorage]"), typically used for long-term slow storage and seeding, as well as all the storage for our per-app /config volumes, now backed by 10Gbps nodes with NVMe disks.
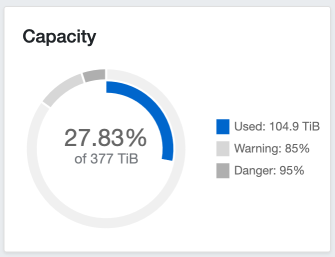
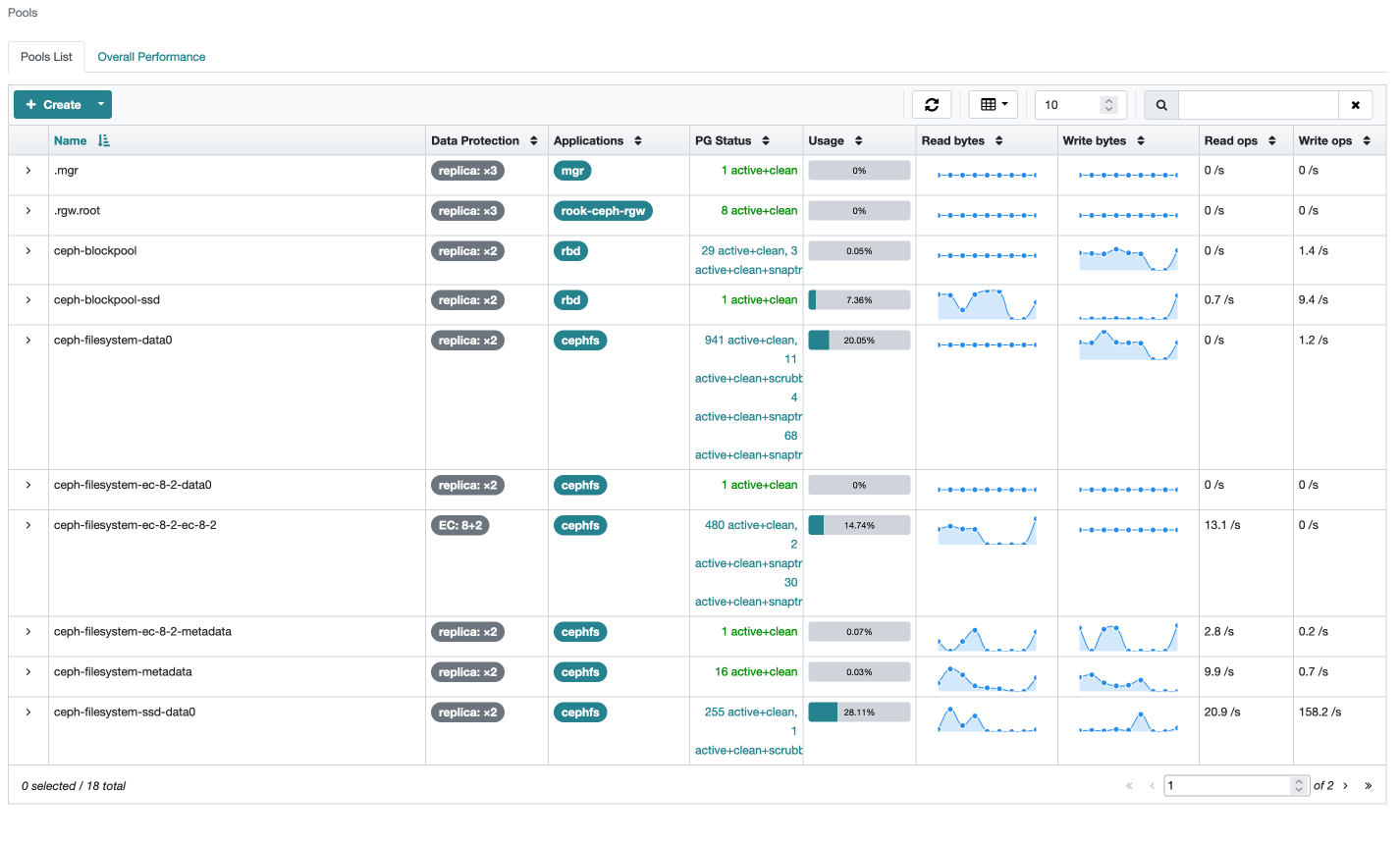
Ceph storage grew 30% during March, with Plex still consuming an inordinate amount of storage with its PhotoTranscoder folder.
The impact of the migration of data from CephFS to Ceph RBD storage can be seen in the change in the size of the ceph-blockpool-ssd and ceph-filesystem-ssd-data0 pools between the two periods.
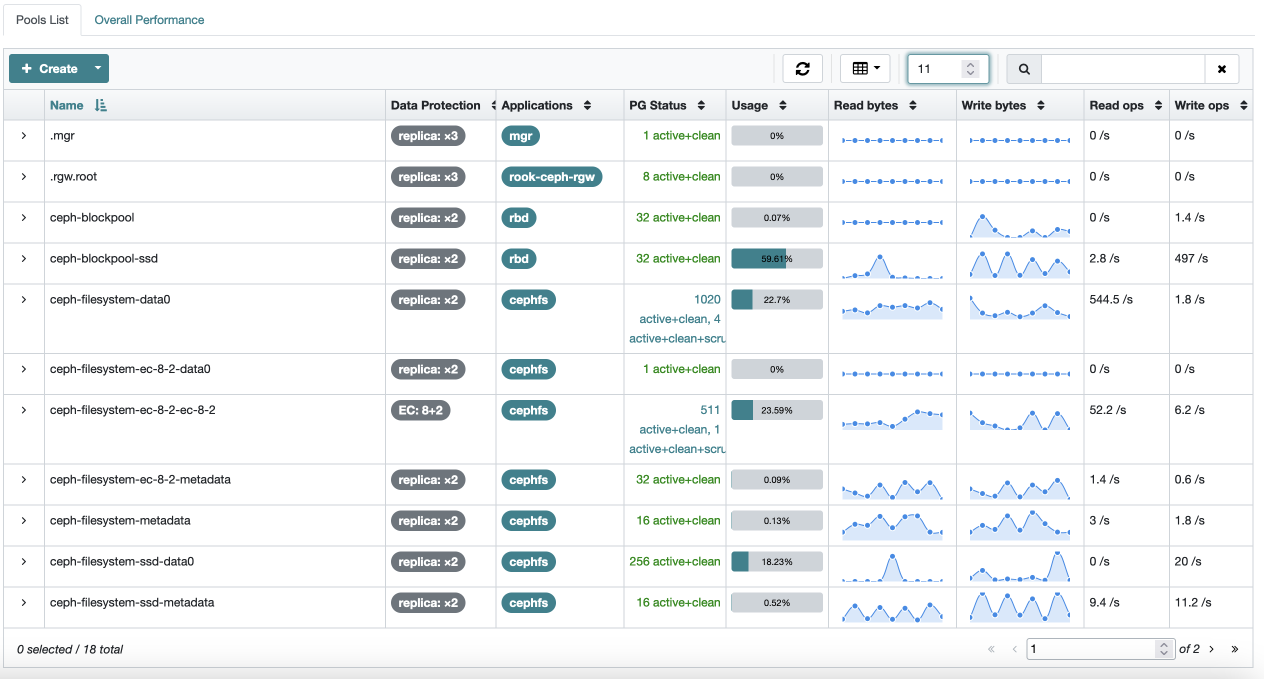
Last month (Feb 2024)'s for comparison:
Retrospective
CephFS to Ceph RBD migrations
In early March, we started to run into I/O contention for the NVMe-backed CephFS storage which provides all our app config/metadata. Pragmatically, we migrated the high-touch data (Plex, Radarr, Sonarr, etc) from CephFS to CephRBD. This has lost us the ability to "see" into the app data for these apps via FileBrowser (a multi-pod mount), but it's also de-loaded the CephFS metadata servers and relieved the I/O contention.
A future enhancement will restore access to config file via an as-yet-undetermined method (SMB mounts is a strong possibility, but for now we're just enjoying the stability)
Ceph PGP surgery
The ceph migration didn't fully alleviate the I/O contention, which culminated in a 10-hour shutdown for Ceph surgery. In the end the problem was here:

When the 10Gi NVMe nodes were initially setup, and the Ceph block pools created, the default PG size of the pool was 1, which was a terrible default and would never perform as intended. We didn't notice this until load was introduced, since NVMe + 10Gi is ... fast.
Updating pgp_num on the pool to 32 has made ceph able to properly balance storage across the nodes again, and since the surgery, we've had no further I/O issues. This configuration may not (yet) be optimal, but it can now be addressed as an iterative improvement, rather than a user-affecting fault.
Bugs and suggestions on GitHub
As pointed out in the last report, Discord was becoming unwieldy for tracking bugs and suggestions, so we've moved these into a GitHub project.
Bugs and suggestions can now be added here.
Stability fixes
One of the take-aways from the "growing pains" in March was that with our volume of users (400+ subscriptions now, and close to 4000 pods), we needed a way to test changes that was somewhere in-between "bleeding-edge-everything-breaks" and "slow-and-steady". With a mind to increasing stability, we've added a "beta" channel to allow adventurous users to beta-test new apps / changes, sometimes for several days, before they're rolled out to "gen-pop" 
Repricing prep
We finished off March 2024 by working on a transparent pricing document, detailing our method and current expenses, which can be found here.
The April 2024 pricing model was informed by usage analysis / reporting, as well as community feedback during the period. Reception from the community was generally positive (our expenses and not-yet-profitable status are clear to see), with the most common request being discounted prices for longer-term commitments.
This has led to the current pricing which is now live on the store, with 20%, 30%, 40% and 50% discounts applied to 1-month, 3-month, 6-month, and 1-year prepaid subscriptions, respectively.
What's coming up?
PostgreSQL support for the Aars
Radarr, Sonarr, etc all now have built-in support for PostgreSQL as a replacement to the troublesome and easy-to-corrupt SQLite database they come with by default. To support our KnightCrawler database, I've started using CloudNativePG (CNPG) for full-lifecycle database management. With a simple CR, CNPG will establish a highly-available PostgreSQL cluster, including automated failover, incremental and automatic backups to local snapshots and to an S3 bucket.
This declarative approach to creating a PostgreSQL database could allow us to, in bulk, create individual database for Arr instances, such that setup is still fully automatic, and users just "get" the PostgreSQL-enabled instances. This was bumped back during March, but should see good traction in April!
Backlog of suggestions
After the repricing is done and any loose ends tied up, we'll work on the list of outstanding suggestions.
The most promising candidates are suggestions which enhance our existing apps, such as Recyclarr, and more rclone-based mounts.
Offering free demos
Nothing gets my attention on a new app like a live demo. I've considered reaching out to open source projects who don't have their own online demo, and offering to host a self-resetting demo for them.
This approach has been successful with the Stremio Addons, and I think it'd be effective at gaining exposure to more niche communities.
A hosted demo would provide their potential users the opportunity to evaluate the app "live", and would also drive more traffic / recognition / SEO juice towards ElfHosted.
If you've got an open-source, self-hosted app and you'd like a free demo instance hosted, hit me up!
(We are currently donating torrent hosting to https://freerainbowtables.com)
Your ideas?
Got ideas for improvements? I'd love to hear them, post them in #elf-suggestions!
How to help
If you'd like to make a donation in recognition of our infrastructure costs, our open-source resources, or our friendly support, a simple donation product is available at https://store.elfhosted.com/product/elf-love/ 
Another effective way to help is to drive traffic / organic discovery, by mentioning ElfHosted in appropriate forums such as Reddit's r/selfhosted, r/seedboxes, r/realdebrid, and r/StremioAddons, which is where much of our target audience is to be found!
Join us!
Want to get involved?
Want to get involved? Join us in Discord and come and test-in-production!