Bulk-transfer network load isolated from streaming / realtime apps
Our platform is built on Hetzner auction server nodes, each of which has unlimited bandwidth, but is physically constrained to a 1Gbps NIC. As we've been bringing more subscribers on board, we've started to see occasional poor performance from the streamers (Plex, Jellyfin, Emby), most likely due to congestion on these 1Gbps links.
When you look at the graph below, the problem is immediately apparent (note the change when our maintenance window started):
So, today I added 5 more nodes to the cluster, to address two areas I felt were likely to become resource bottlenecks..
Network bandwidth
Our torrent / NZB clients share our 1Gbps NICs with our streamers, but they're two different types of traffic, and they don't play well together. IMO, it's OK to max out the available bandwidth on a download client, it's "bulk" transfer after all, and whether it arrives at 100MB/s or 50MB/s makes little difference to the user experience, provided downloads complete reasonably and are available when you're ready for them.
Streaming apps need enough bandwidth to be able to direct-play media without stuttering, and delays due to congestion are immediately noticeable, and at the worst time (when you're trying to relax and enjoy your media).
I've added 2 x i7-8700 nodes, each with a total of 14TB storage (2 x 8TB HDDs) and 128GB RAM. These nodes, "orcs", are "tainted" in Kubernetes, such that only our download clients will run on them. The most immediate effect of this change is the de-loading of the regular nodes, "elves", for the rest of our apps, including streaming.
The extra resources available on the orcs will also allow a huge expansion of the temp space available to download clients, as well as a significant bump in RAM allocation, meaning downloads can be more efficiently unpacked to local temp space, processed, and then finally moved to long-term storage (like a storagebox) in the most efficient way possible.
Storage bandwidth
An area of possible congestion which is a little harder to measure is the impact of increasing ElfStorage users on the apps' access to their own config files, libraries, etc. ElfStorage is provided by ceph, off a pool running on HDDs ("dwarves"). Currently the same pool is being used for storing config files, Plex metadata, etc. While I/O load is not that high currently, as more users start using ElfStorage, I'm concerned that I/O is going to become a problem, and negatively impact the performance of all the apps.
I've pulled the trigger on 31 more i7-8700s, each with 2 x 1TB NVMe-SSDs (and 128GB RAM, although that's not important right now). I'm going to put these three "goblins" to work as a second storage pool in ceph for config files and metadata, so that we can avoid congestion on ElfStorage affecting other, un-related apps.
Before and after
Here's what our cluster looked like, yesterday:
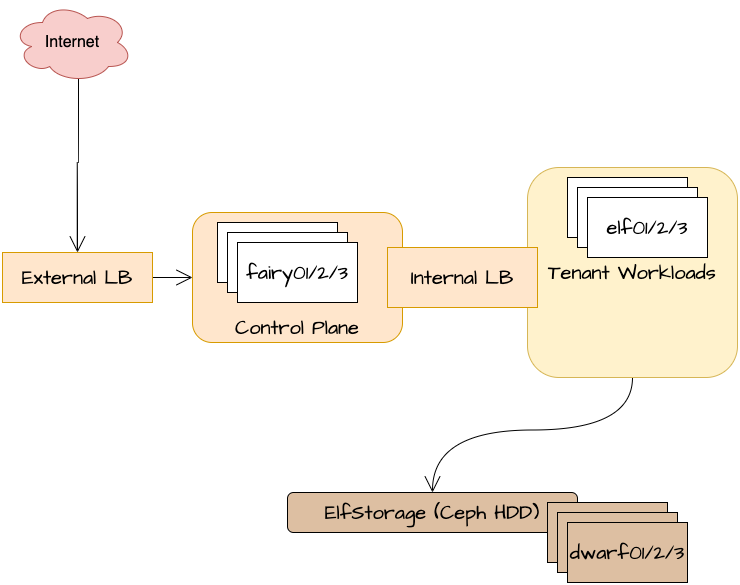
And here's what it looks like today:
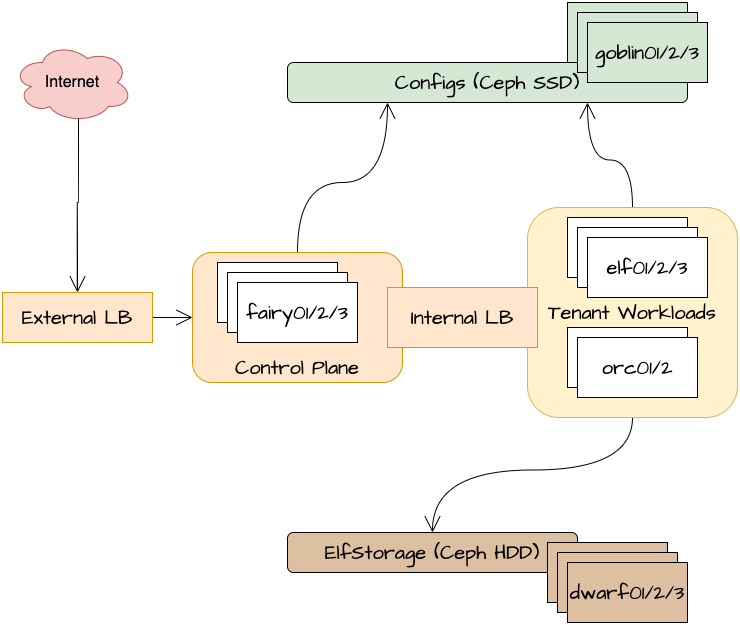
Why now?
Is it smart to add more nodes if ElfHosted isn't making a profit?
That's the question I asked myself when pulling the trigger today! I don't know. To be honest, I may have gotten carried away on the Hetzner Auction Server page 
But the way I think about it, I'm not going to attract more users to a service which doesn't perform reliably, and streaming your media is about the most critical / high-profile of all our services!
Also, Black Friday is around the corner, and I've been trying to increase visibility with a "BlackFlagDay" special offer on Reddit, and (once I'me approved) on LES.
I'm anticipating some more subscriptions and "tyre-kickers", and I want the platform to be able to handle this without impacting existing happy users 
Today's scoreboard
| Metric | Numberz |
|---|---|
| Healthy tenant pods | 648 |
| Total subscribers 2 | 70 |
| Storageboxes mounted | 17 |
| Rclone mounts | 5 |
| Bugz squished | 0 |
| New toyz | 0 |
Summary
As always, thanks for building with us!
-
3 is the minimum number of nodes to kick-start a resilient storage pool, since we need 2 replicas of each object, and we want to be able to tolerate the loss of a one node without incurring Ceph's io single-threaded, deer-in-the-headlights mode! ↩
-
Includes users testing the platform with $10 free ElfBuckz ↩