Health alerts, badges, GDrive & WebDAV
Just after I bragged yesterday about the increase in pod count, a bug in the webhook handler caused all subsequent orders to get stuck for ~10 hours! If you'd made a change to your subscription during that time, or signed up, you'd have been wondering where your apps went and why nothing provisioned 
Here's what this looked like...
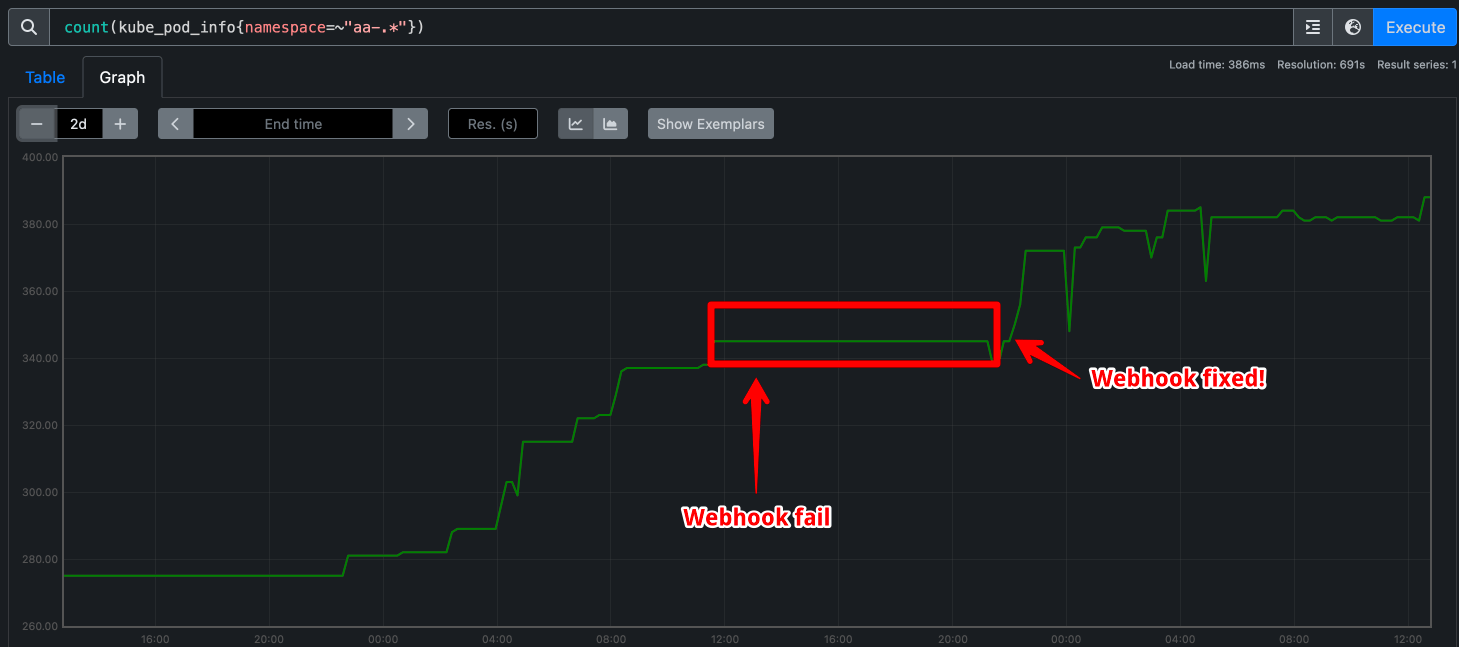
I squished the bug and hardened the webhook receiver, then tried to process all the backlogged orders. If you received a few duplicate confirmations this morning, that'll be why. If you placed an order and didn't receive it, try cancelling and then resuming the order to force the update.
Health Alerts
What I didn't expect is how many users would sign up for service and not jump into Discord, or get in touch when things didn't work. Discord makes announcmements / updates so easy, that I realized I hadn't invested enough effort into other communications channels, like email (an emailed welcome on purchase is still on the to-do-asap list)
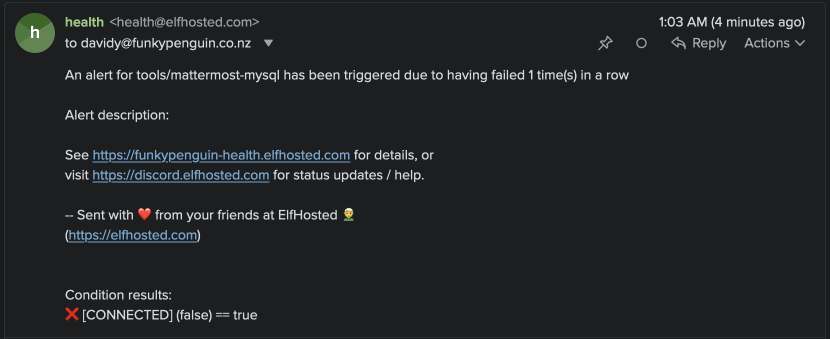
Since we're still at beta-level stability, and I don't want a reputation for being unreliable, I wanted a way to alert users to changes to their apps' health - I discovered that we can do this with our existing health dashboard (using Gatus), by enabling email alerting. After a brief poll of the #elf-friends channel, I've now turned this on, so if you've got any unhealthy apps (and there are a few still), you'll get one email after 20m of downtime, and one email upon recovery.
Here's what the email looks like...
Also, since everyone loves badges, I permitted the Gatus API to work without SSO (all it exposes is availability metrics), so that you can embed your health badges anywhere and admire them in public, like these live badges from my own account:
| Example | Explanation |
|---|---|
| My mattermost is broken, need to do some migration | |
| My plex is not (guess who's prioritized more!) | |
| I've been using Navidrome to test alerts |
Tip
You can get your own badges by clicking on the name of each service in your health dashboard 
What's also handy about the Gatus implementation is that we can define a maintenance period during which alerts will not be sent - I've configured this, so that during our soon-to-be-established daily maintenance window1, we won't get any unnecessary alerts!
maintenance:
start: 10:00 # 10am UTC = 10pm NZDT
duration: 1h
TL;DR
Other Improvementz
 You can now mount Google Drive to your ElfHosted apps - purchase one of these. This is tested and working.
You can now mount Google Drive to your ElfHosted apps - purchase one of these. This is tested and working.- We've also got an as-yet-untested product to mount WebDAV URLs. Purchase one of these bad boys to try it out!
(Still) Next Up
- Add a link on the store user account page to the app dashboard
- Send email to user with link to their dashboard
- Make checkout fields work better with browser auto-fill (is this a Woocommerce/Wordpress issue?)
- Add Wordpress caching plugin to reduce load issues (at one point, the DO node running Wordpress stopped responding for 5 min!)
Thanks for building with us - stay tuned!
-
For applying upstream updates to apps ↩